DB에서 ORDER BY 사용 시 Out of Sort Memory 문제
DB를 사용하다 보면 ORDER BY 를 피할 수 없습니다.
하지만 무심코 사용하면 Out of Sort Memory (OOSM) 문제가 발생할 수 있습니다.
하지만 무심코 사용하면 Out of Sort Memory (OOSM) 문제가 발생할 수 있습니다.
실습 환경
해당 테스트는 MySQL8와 Ruby Console을 사용했습니다.
해당 테스트는 MySQL8와 Ruby Console을 사용했습니다.
아래와 같은 스키마를 준비했습니다.
CREATE TABLE posts ( id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY, title VARCHAR(255), content JSON, -- 무거운 컬럼 (1MB) category VARCHAR(100), author_name VARCHAR(100), view_count INT DEFAULT 0, created_at DATETIME, INDEX index_posts_on_created_at (created_at) );
content 컬럼에 약 1MB 크기의 JSON 데이터를 넣고, 총 11개 row를 생성했습니다.
테스트 1: PK(id)로 ORDER BY
SELECT * FROM posts ORDER BY id LIMIT 11

정상적으로 동작합니다!!!
테스트 2: 인덱스 없는 컬럼(title)으로 ORDER BY
SELECT * FROM posts ORDER BY title LIMIT 11;

Out of Sort Memory 에러 발생!.....
테스트 3: 인덱스 있는 컬럼(created_at)으로 ORDER BY
SELECT * FROM posts ORDER BY created_at LIMIT 11;
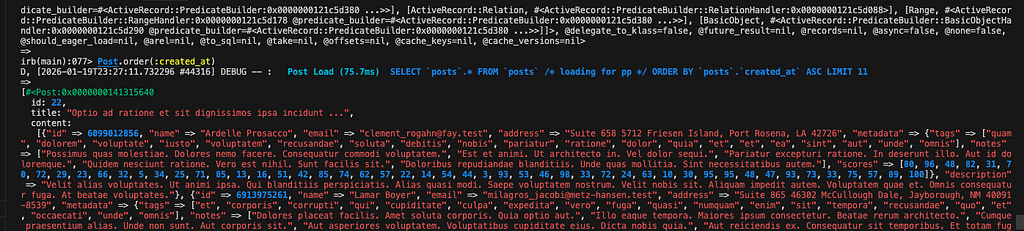
정상 동작!!! OOSM이 발생하지 않습니다.
테스트 4: content를 제거하고 title로 정렬
SELECT ... FROM posts ORDER BY title LIMIT 11;

정상 동작!!! OOSM이 발생하지 않습니다.
왜 이런 차이가 발생할까?
이 예시에서 에러가 발생하는 근본적인 이유는 content 컬럼의 크기가 1MB로 매우 크기 때문입니다. MySQL이나 PostgreSQL 같은 데이터베이스는 정렬(Order By)을 수행할 때 sort_buffer_size(MySQL) 또는 work_mem(PostgreSQL)이라는 할당된 메모리 공간을 사용합니다.
일반적으로 정렬할 전체 데이터 크기가 버퍼보다 크면, DB는 디스크(임시 파일)를 사용하는 방식을 통해 느리지만 정렬을 성공시킵니다. 하지만 데이터 한 행의 크기 자체가 버퍼 크기보다 클 경우에는 Out of Sort Memory (OOSM) 오류가 발생하게 됩니다.
현재 제 DB의 --sort_buffer_size는 262,144 Byte (256KB)로 설정되어 있습니다. 따라서 1MB에 달하는 Row를 메모리에 올릴 수 없어 에러가 발생하는 것입니다.
정확한 검증을 위해 Row의 크기를 각각 100KB, 250KB, 300KB로 조정하여 테스트를 진행해보겠습니다. (참고: 단일 Row 조회 시에는 정렬 최적화로 인해 Sort Buffer 이슈가 잘 드러나지 않으므로, OR 조건을 사용하여 복수의 Row를 스캔하도록 유도했습니다.)
1. 정상 케이스 (Row Size < Buffer Size)
현재 제 DB의 --sort_buffer_size는 262,144 Byte (256KB)로 설정되어 있습니다. 따라서 1MB에 달하는 Row를 메모리에 올릴 수 없어 에러가 발생하는 것입니다.
정확한 검증을 위해 Row의 크기를 각각 100KB, 250KB, 300KB로 조정하여 테스트를 진행해보겠습니다. (참고: 단일 Row 조회 시에는 정렬 최적화로 인해 Sort Buffer 이슈가 잘 드러나지 않으므로, OR 조건을 사용하여 복수의 Row를 스캔하도록 유도했습니다.)
1. 정상 케이스 (Row Size < Buffer Size)
먼저 100KB와 250KB 크기의 데이터를 OR 조건으로 조회하고, 인덱스가 없는 title 컬럼으로 정렬해 보겠습니다. 제 설정된 sort_buffer_size는 256KB이므로, 250KB 데이터까지는 버퍼 안에 수용 가능합니다.
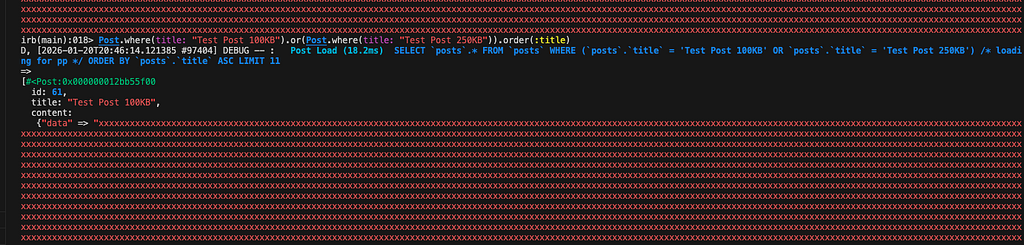
보시는 것처럼 OOSM 없이 정상적으로 조회되는 것을 확인할 수 있습니다.
2. 에러 케이스 (Row Size > Buffer Size)
이번에는 100KB와 300KB 데이터를 조회해 보겠습니다. 300KB는 버퍼 크기(256KB)를 초과합니다.
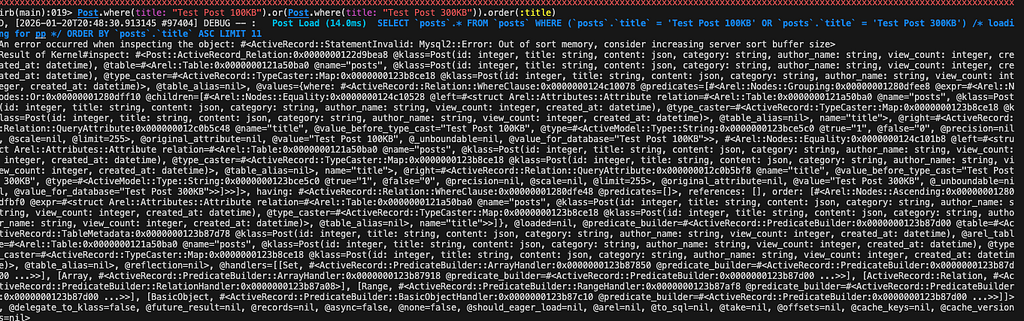
예상대로 OOSM 에러가 발생했습니다. 한 Row의 크기가 할당된 정렬 버퍼를 초과했기 때문입니다.
그렇다면 PK나 인덱스를 기준으로 정렬할 때는 왜 이런 문제가 발생하지 않을까요?
인덱스는 데이터가 이미 '정렬된 상태'로 저장된 지도와 같기 때문입니다.
데이터베이스 입장에서는 별도의 정렬 연산을 수행하며 메모리 버퍼를 사용할 필요 없이, 인덱스 순서대로 데이터를 읽기만 하면 됩니다.
이 덕분에 메모리 사용량은 최소화되고 속도는 매우 빠르고 안정적입니다.
데이터베이스 입장에서는 별도의 정렬 연산을 수행하며 메모리 버퍼를 사용할 필요 없이, 인덱스 순서대로 데이터를 읽기만 하면 됩니다.
이 덕분에 메모리 사용량은 최소화되고 속도는 매우 빠르고 안정적입니다.
결론
정렬해야 할 데이터의 한 행(Row) 크기가 할당된 정렬 버퍼(Sort Buffer)보다 크다면 OOSM 오류가 발생할 수 있습니다.
정렬해야 할 데이터의 한 행(Row) 크기가 할당된 정렬 버퍼(Sort Buffer)보다 크다면 OOSM 오류가 발생할 수 있습니다.
저는 이러한 OOSM 현상을 방지하기 위한 접근 방식을 크게 두 가지로 분류합니다. (물론 버퍼 사이즈를 늘리는 등 다른 방법도 존재합니다.)
1. 인덱스(Index)를 활용
가장 정석적인 방법입니다.
이미 정렬된 상태를 유지하는 인덱스를 타게 되면, DB는 별도의 메모리 정렬 과정이나 디스크 부하 없이 매우 빠르게 데이터를 읽어올 수 있습니다.
1. 인덱스(Index)를 활용
가장 정석적인 방법입니다.
이미 정렬된 상태를 유지하는 인덱스를 타게 되면, DB는 별도의 메모리 정렬 과정이나 디스크 부하 없이 매우 빠르게 데이터를 읽어올 수 있습니다.
하지만 서비스 요구사항이 복잡해질수록 정렬 조건 또한 다양해진다는 문제가 있습니다.
그때마다 모든 조건에 맞춰 인덱스를 추가하는 것은 현실적으로 한계가 있습니다.
인덱스가 늘어날수록 INSERT나 UPDATE 같은 쓰기 성능이 저하되고, 불필요한 저장 공간 낭비가 발생하기 때문입니다.
2. 조회 쿼리 최적화
무거운 컬럼은 목록 조회(Select)에서 제외 또는
두 번째는 목록 조회 시에는 필요한 가벼운 컬럼만 가져오고, 무거운 컬럼은 상세 조회(FindOne) 시에만 가져오도록 쿼리와 설계를 분리하는 것입니다.
이를 위해서는 무거운 데이터를 별도로 관리하는 설계가 동반되어야 합니다. 실제로 현재 이 블로그도 게시글의 제목(title)과 본문(content)을 별도 테이블로 분리하여 관리하고 있습니다.
목록을 훑을 때는 가벼운 제목만 조회하고, 사용자가 게시글을 클릭하여 들어갈 때만 무거운 본문 데이터를 가져옵니다.
그때마다 모든 조건에 맞춰 인덱스를 추가하는 것은 현실적으로 한계가 있습니다.
인덱스가 늘어날수록 INSERT나 UPDATE 같은 쓰기 성능이 저하되고, 불필요한 저장 공간 낭비가 발생하기 때문입니다.
2. 조회 쿼리 최적화
무거운 컬럼은 목록 조회(Select)에서 제외 또는
두 번째는 목록 조회 시에는 필요한 가벼운 컬럼만 가져오고, 무거운 컬럼은 상세 조회(FindOne) 시에만 가져오도록 쿼리와 설계를 분리하는 것입니다.
이를 위해서는 무거운 데이터를 별도로 관리하는 설계가 동반되어야 합니다. 실제로 현재 이 블로그도 게시글의 제목(title)과 본문(content)을 별도 테이블로 분리하여 관리하고 있습니다.
목록을 훑을 때는 가벼운 제목만 조회하고, 사용자가 게시글을 클릭하여 들어갈 때만 무거운 본문 데이터를 가져옵니다.
물론 테이블을 분리하면 데이터를 합칠 때 JOIN 연산이나 추가 쿼리가 필요하다는 번거로움은 존재합니다.
하지만 대량의 데이터를 빈번하게 정렬하고 조회해야 하는 목록 기능에서 무거운 컬럼을 배제하는 것은 서비스의 전체적인 안정성을 확보하는 데 매우 유리합니다.
하지만 대량의 데이터를 빈번하게 정렬하고 조회해야 하는 목록 기능에서 무거운 컬럼을 배제하는 것은 서비스의 전체적인 안정성을 확보하는 데 매우 유리합니다.
정답은 없습니다
저는 개인적으로는 두 번째 방법인 무거운 컬럼을 제외하는 방식을 더 선호합니다.
무거운 텍스트 데이터가 포함된 채로 정렬을 수행해야 한다면, 이는 애초에 스키마 설계나 쿼리 패턴을 다시 점검해봐야 할 신호일 수 있기 때문입니다.
무거운 텍스트 데이터가 포함된 채로 정렬을 수행해야 한다면, 이는 애초에 스키마 설계나 쿼리 패턴을 다시 점검해봐야 할 신호일 수 있기 때문입니다.
결국 상황에 따라 인덱스로 해결할지, 쿼리에서 컬럼을 뺄지, 혹은 테이블 구조를 정규화하여 분리할지를 선택해야 합니다.
중요한 것은 내 시스템의 데이터 특성과 쿼리 실행 계획(Explain)을 수시로 확인하며, 현재 상황에 가장 적절한 균형점을 찾는 것입니다.
대규모 트래픽을 견디는 시스템들은 보통 이러한 고민과 트레이드오프 과정을 통해 각자만의 최적화 방식을 찾아내곤 합니다.
대규모 트래픽을 견디는 시스템들은 보통 이러한 고민과 트레이드오프 과정을 통해 각자만의 최적화 방식을 찾아내곤 합니다.
댓글 (0)
아직 댓글이 없습니다.
댓글 작성